 (Photo by Aaron Burden on Unsplash)
(Photo by Aaron Burden on Unsplash)
这两天将半年前写的爬虫代码重构了一下,本来以为要不了多久,结果前前后后花了我将近4个小时的时间。
无力吐槽!:sob:
半年前的代码是一个面向过程的处理,几个函数顺序执行,最终慢悠悠地把PDF生成出来,功能都齐全,但是可读性和拓展性极差。现在全部改为面向对象处理,将requests.Session操作剥离出来作为Crawler类,将解析网页的操作剥离出来作为Parse类,结构清楚了很多,耦合度(较之前)大大降低,基本达到我的要求。
整体功能实现后,我写了一个cache函数,将Session操作缓存起来方便后续复用,本地调试成功,但最终没有采用。我的设想是在一定期限内将Session操作常驻内存,每次执行前检查缓存中有没有,有的话就直接用,没有才新建。但我这个cache函数在程序执行完后,缓存的内容直接被释放,每次执行都需要新建Session连接。这几天在学习Redis,估计我想要的效果得用redis才能实现。
在将网页生成HTML文件到本地后,使用pdfkit工具将HTML文件转换为PDF很耗费时间,这一点请大家注意。
环境准备
macOS 10.11.6 + Anaconda Navigator 1.7.0+ Python 2.7.12 + Sublime 3.0
技术要点
- Requests会话处理
- BeautifulSoup网页解析
- pdfkit工具(注意,一定要先安装wkhtmltopdf这个工具包)
- decorator装饰器
代码实现
|
|
执行结果
生成的HTML文件和PDF文件如下。
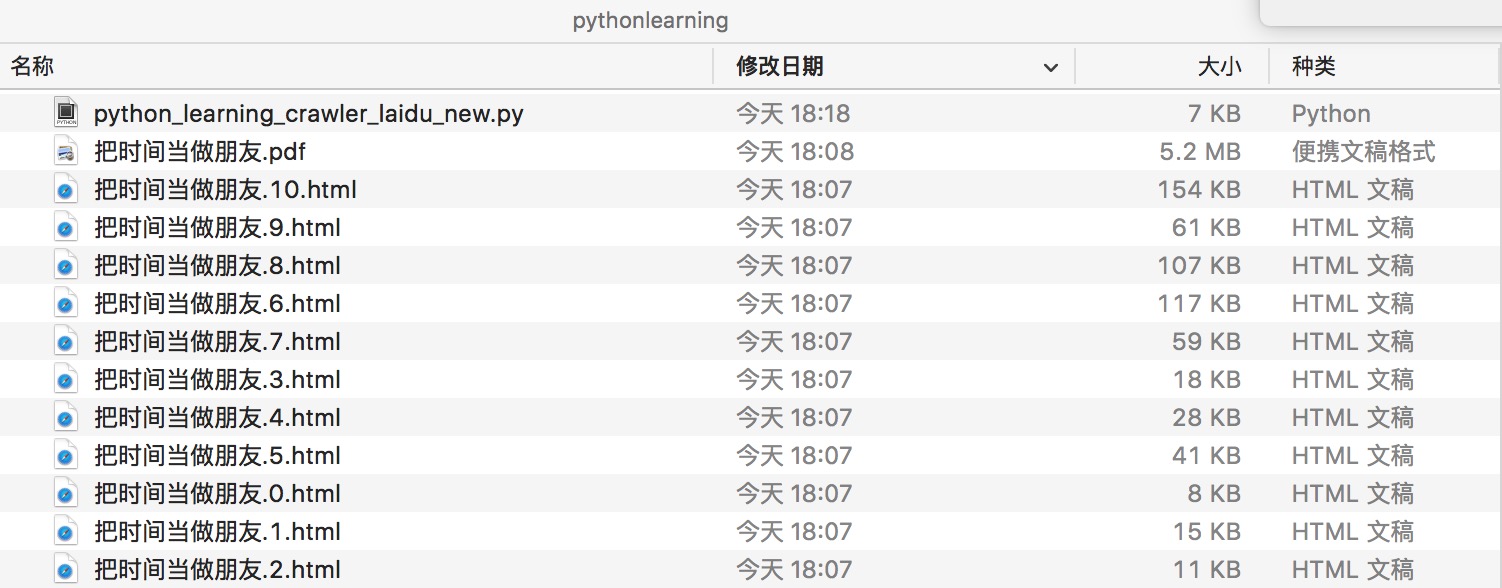
生成PDF文件预览,注意红色方框第5章第4节”逆命题”出现错位,我检查过,不是网页解析的问题,是电子书HTML文件源码中”逆命题”那一节的文本标签被错误定义为”h1”,手工将文件改为”h2”,再生成PDF就能修复这个问题。
输出的Log如下。
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990runfile('/Users/jacksonshawn/PythonCodes/pythonlearning/python_learning_crawler_laidu_new.py', wdir='/Users/jacksonshawn/PythonCodes/pythonlearning')*** Function Name:*** run*** PGM begin ***---xsrf---: f8EMOPQer81CI4xwn3mQ8ccqnyLikVRNQAMk5887MAIN chapter_index: 0MAIN chapter_url: http://laidu.co/books/7fa8fcfa612989251007dafde19a1e86/index.htmlMAIN chapter_name: 把时间当做朋友.0.htmlMAIN chapter_index: 1MAIN chapter_url: http://laidu.co/books/7fa8fcfa612989251007dafde19a1e86/Preface.htmlMAIN chapter_name: 把时间当做朋友.1.htmlMAIN chapter_index: 2MAIN chapter_url: http://laidu.co/books/7fa8fcfa612989251007dafde19a1e86/Forword.htmlMAIN chapter_name: 把时间当做朋友.2.htmlMAIN chapter_index: 3MAIN chapter_url: http://laidu.co/books/7fa8fcfa612989251007dafde19a1e86/Chapter0.htmlMAIN chapter_name: 把时间当做朋友.3.htmlMAIN chapter_index: 4MAIN chapter_url: http://laidu.co/books/7fa8fcfa612989251007dafde19a1e86/Chapter1.htmlMAIN chapter_name: 把时间当做朋友.4.htmlMAIN chapter_index: 5MAIN chapter_url: http://laidu.co/books/7fa8fcfa612989251007dafde19a1e86/Chapter2.htmlMAIN chapter_name: 把时间当做朋友.5.htmlMAIN chapter_index: 6MAIN chapter_url: http://laidu.co/books/7fa8fcfa612989251007dafde19a1e86/Chapter3.htmlMAIN chapter_name: 把时间当做朋友.6.htmlMAIN chapter_index: 7MAIN chapter_url: http://laidu.co/books/7fa8fcfa612989251007dafde19a1e86/Chapter4.htmlMAIN chapter_name: 把时间当做朋友.7.htmlMAIN chapter_index: 8MAIN chapter_url: http://laidu.co/books/7fa8fcfa612989251007dafde19a1e86/Chapter5.htmlMAIN chapter_name: 把时间当做朋友.8.htmlMAIN chapter_index: 9MAIN chapter_url: http://laidu.co/books/7fa8fcfa612989251007dafde19a1e86/Chapter6.htmlMAIN chapter_name: 把时间当做朋友.9.htmlMAIN chapter_index: 10MAIN chapter_url: http://laidu.co/books/7fa8fcfa612989251007dafde19a1e86/Chapter7.htmlMAIN chapter_name: 把时间当做朋友.10.html*** Function Name:*** transfer_html_2_pdf*** Transfer_html_2_pdf begin ***Loading pages (1/6)libpng warning: iCCP: known incorrect sRGB profile ] 50%libpng warning: iCCP: known incorrect sRGB profile ] 52%libpng warning: iCCP: known incorrect sRGB profile ] 52%libpng warning: iCCP: known incorrect sRGB profile ] 56%libpng warning: iCCP: known incorrect sRGB profile ] 56%libpng warning: iCCP: known incorrect sRGB profile ] 56%libpng warning: iCCP: known incorrect sRGB profile ] 59%libpng warning: iCCP: known incorrect sRGB profile ] 60%libpng warning: iCCP: known incorrect sRGB profile ] 60%libpng warning: iCCP: known incorrect sRGB profile ] 61%libpng warning: iCCP: known incorrect sRGB profile ] 62%libpng warning: iCCP: known incorrect sRGB profile ] 63%libpng warning: iCCP: known incorrect sRGB profile ] 64%libpng warning: iCCP: known incorrect sRGB profile ] 64%libpng warning: iCCP: known incorrect sRGB profile ] 64%libpng warning: iCCP: known incorrect sRGB profile ] 64%libpng warning: iCCP: known incorrect sRGB profile ] 66%libpng warning: iCCP: known incorrect sRGB profile ] 68%libpng warning: iCCP: known incorrect sRGB profile ] 69%libpng warning: iCCP: known incorrect sRGB profile ] 69%libpng warning: iCCP: known incorrect sRGB profile ] 70%libpng warning: iCCP: known incorrect sRGB profile ] 71%libpng warning: iCCP: known incorrect sRGB profile ] 71%libpng warning: iCCP: known incorrect sRGB profile ] 71%libpng warning: iCCP: known incorrect sRGB profile ] 72%libpng warning: iCCP: known incorrect sRGB profile ] 72%libpng warning: iCCP: known incorrect sRGB profile ] 73%libpng warning: iCCP: known incorrect sRGB profile ] 73%libpng warning: iCCP: known incorrect sRGB profilelibpng warning: iCCP: known incorrect sRGB profile ] 76%libpng warning: iCCP: known incorrect sRGB profile ] 78%libpng warning: iCCP: known incorrect sRGB profile ] 80%libpng warning: iCCP: known incorrect sRGB profile=> ] 84%libpng warning: iCCP: known incorrect sRGB profile===> ] 88%libpng warning: iCCP: known incorrect sRGB profile====> ] 89%libpng warning: iCCP: known incorrect sRGB profile=====> ] 90%libpng warning: iCCP: known incorrect sRGB profile=====> ] 91%libpng warning: iCCP: known incorrect sRGB profile======> ] 93%libpng warning: iCCP: known incorrect sRGB profile========> ] 95%libpng warning: iCCP: known incorrect sRGB profile========> ] 96%libpng warning: iCCP: known incorrect sRGB profile==========>] 99%Counting pages (2/6)Resolving links (4/6)Loading headers and footers (5/6)Printing pages (6/6)Done*** Transfer_html_2_pdf end ****** Function Takes:*** 0:01:09.791587 Time*** PGM end ****** Function Takes:*** 0:01:16.134701 Time
总结
- 使用pdfkit生成PDF文件,必须要先安装wkhtmltopdf这个工具。pdfkit只是一个入口程序,真正生成PDF这些脏活累活,都是wkhtmltopdf完成的。安装wkhtmltopdf成功后,在transfer_html_2_pdf函数中一定要指定正确的调用路径。
- 目前还没有设置缓存机制,这两天在看Redis,打算后面加一个缓存处理。
- Crawler类里面使用的@classmethod装饰器,其实完全可以拿掉不要,我测试过,不用@classmtehod也没问题。用这个显得高大上,装逼效果更好。:smile:
- Parse类里面用到的decorator装饰器,其实可以剥离出来成为一个单独的类,进一步降低耦合度。
- 可以使用profile.run(‘p.run()’)跑性能检测作业。目前最耗费时间的操作在生成PDF文件那一步,爬取网页操作其实要不了多少时间。
附GitHub地址:
参考资料:
