这几天将一个Python Airflow Project部署到了本机K8S环境,前天一切都很正常。昨天开始出现了这样一个异常情况。
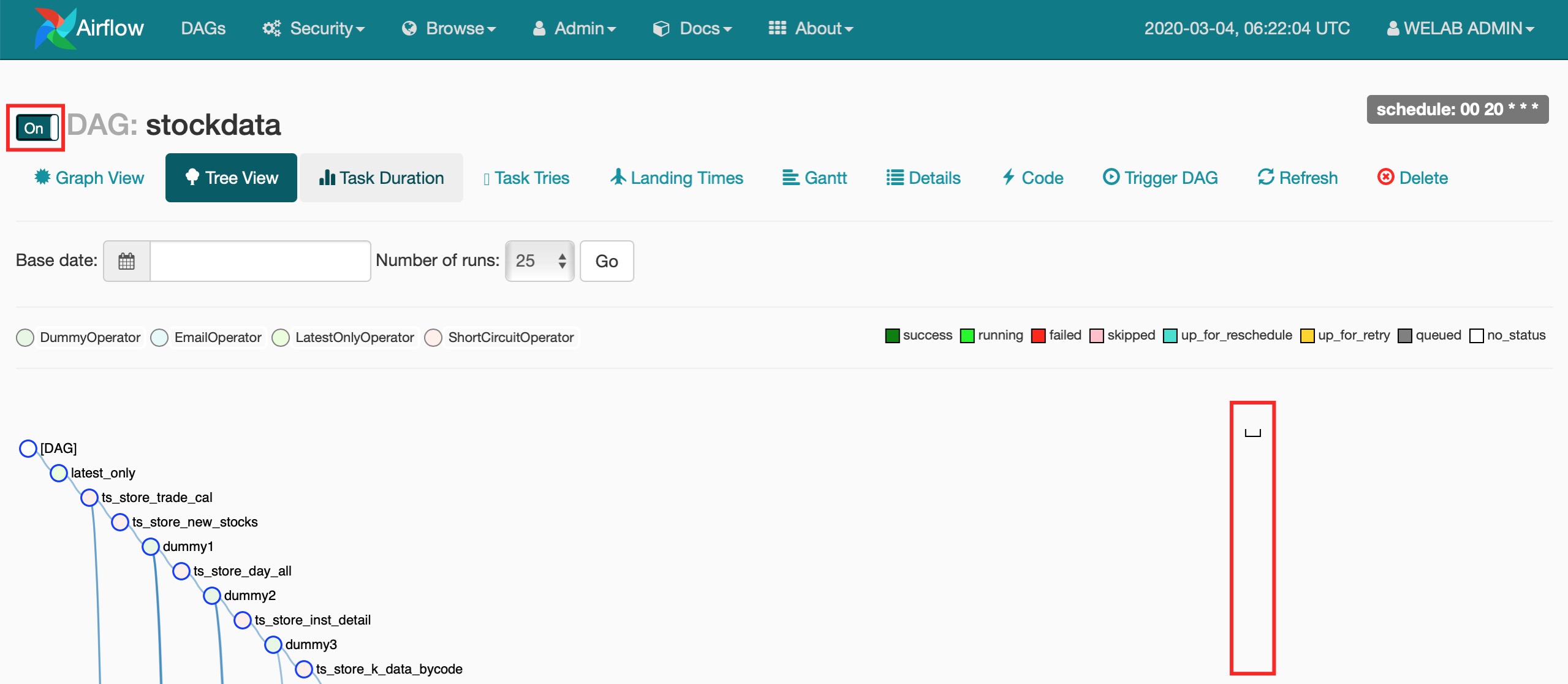
一般情况下,在Airflow里打开Dag的开关后,调度器会自动trigger一次Dag Run,但昨天开始Airflow的调度器自动trigger一直不成功。
(图1)
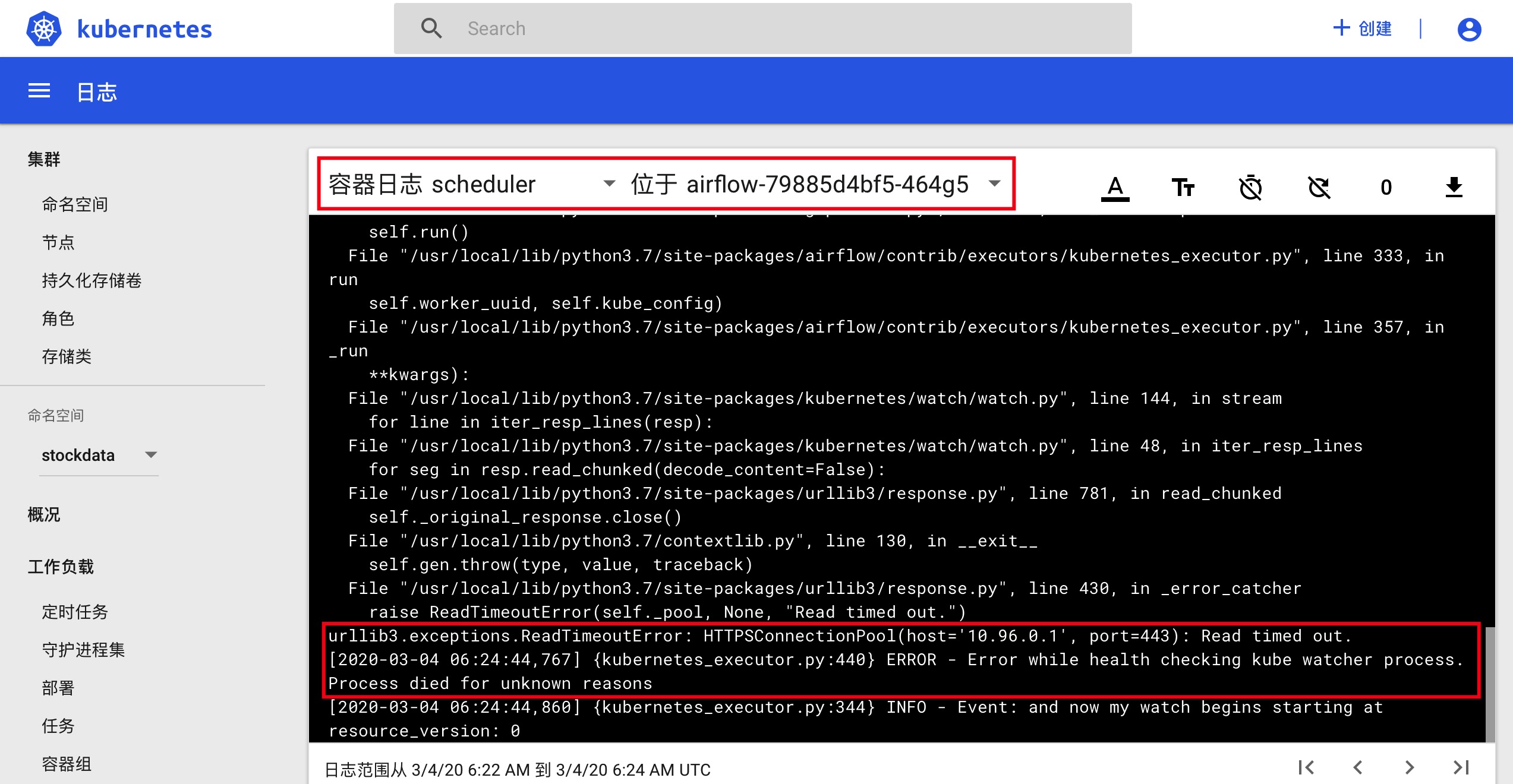
使用kubectl proxy和kubectl -n kube-system describe secret default| awk '$1=="token:"{print $2}'进入K8S Dashboard,查看容器组(也就是Pod)airflow-79885d4bf5-464g5里shceduler这个容器日志,发现如下报错信息。
(图2)
其实不用K8S Dashboard,使用kubectl logs airflow-79885d4bf5-464g5 scheduler -n stockdata命令也可以查出相关的报错。
|
|
刚开始翻Airflow的源码,是kubernetes_executor执行器报的错,没发现什么有价值的信息。一番seacrh之后,发现10.96.0.1是K8S集群Master节点的IP地址,是Pod与Master节点之间的连通性出了问题,但如果在图1里,手工点击”Trigger DAG”发起一次Dag Run,调度器能够将Dag调度成功,是不是可以认为Pod与Master的初始网络链接出了问题。
使用kubectl cluster-info查看集群信息。
|
|
查看节点信息。
|
|
查看K8S kube-system这个namespace里的Pod信息。
|
|
依次检查两个coredns Pod的日志,发现下面这个异常情况。
|
|
查看service信息
|
|
使用@dannymk给出的方法,删除services之后,kubernetes马上又重新被create一个,并没有真正解决问题。
查看所有endpoints信息
|
|
最后查看所有services时,发现除了kubernetes这个service使用443端口外,其它compose-api和kubernetes-dashboard也使用443端口,会不会是这两个服务将端口占用了导致的文 it。
|
|
使用kubectl delete svc/compose-api -n docker和kubectl delete svc/kubernetes-dashboard -n kube-system将这两个使用443端口的service删掉后,以为问题可以就此解决,重启K8S之后,发现问题依然存在。
浪费时间太多,以后对K8S熟悉之后再查吧。
参考资料
